Storage that grows without chaos
We organize raw, curated, and serving layers so large datasets remain discoverable and cost-aware.
Big Data Platform
Process high-volume, high-velocity data with distributed systems built for real-time analytics, reliable storage, and business impact.
Overview
Sachak helps teams design big data platforms that store diverse datasets, process massive workloads, and serve analytics without slowing down the business. The result is a foundation for real-time decisions, advanced analytics, and future AI initiatives.
What We Solve
We organize raw, curated, and serving layers so large datasets remain discoverable and cost-aware.
High-volume events, logs, transactions, and telemetry can support both historical analysis and live monitoring.
Analysts, applications, and data science teams get the right serving layer instead of waiting on slow raw storage.
Delivery Blueprint
Profile data volume, concurrency, latency, retention, and query behavior.
Define storage layers, table formats, partitions, catalog strategy, and governance.
Implement batch, streaming, orchestration, and serving jobs for target use cases.
Tune compute, retention, compaction, query patterns, and monitoring over time.
Core Capabilities
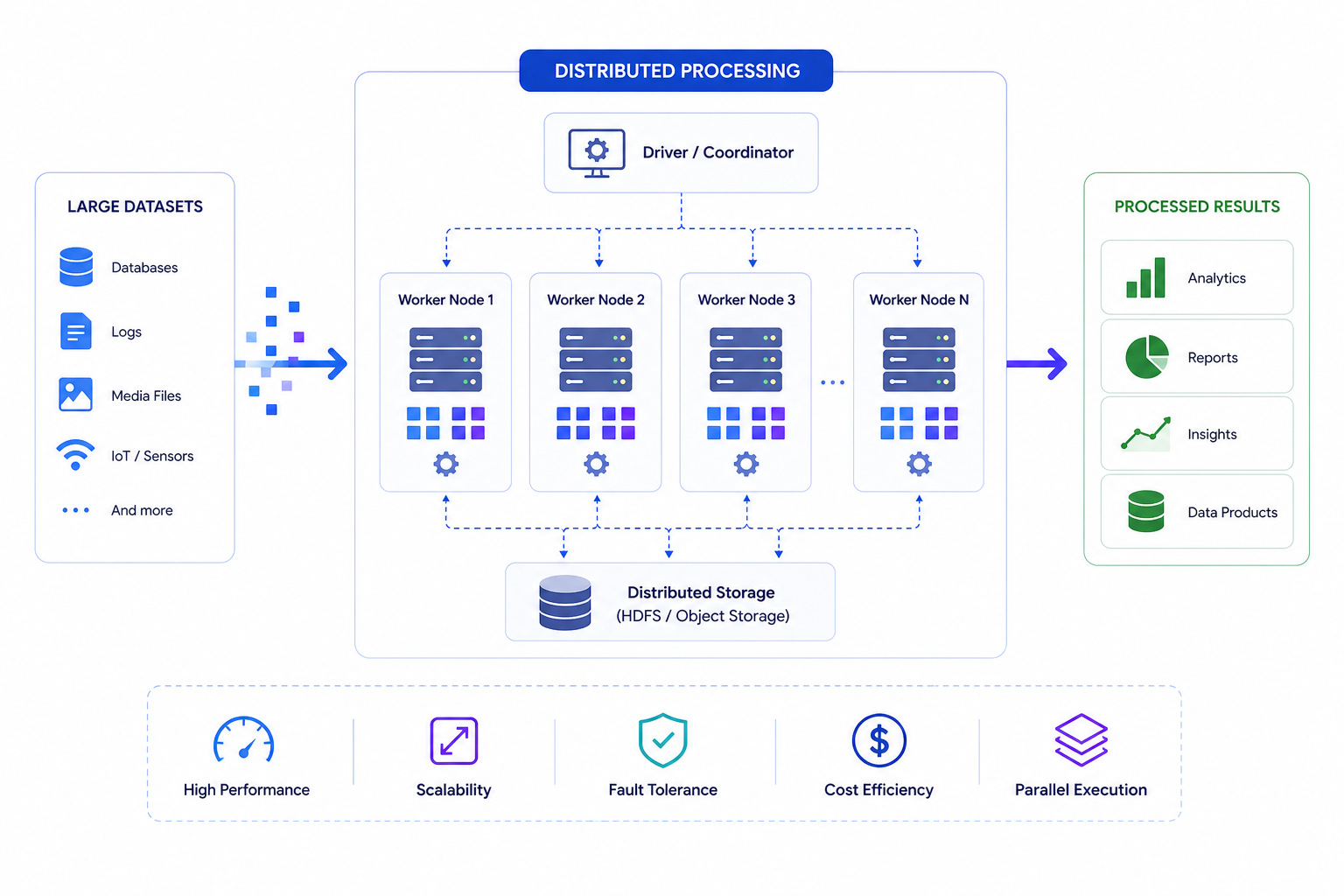
Run parallel computation across scalable clusters for large datasets.
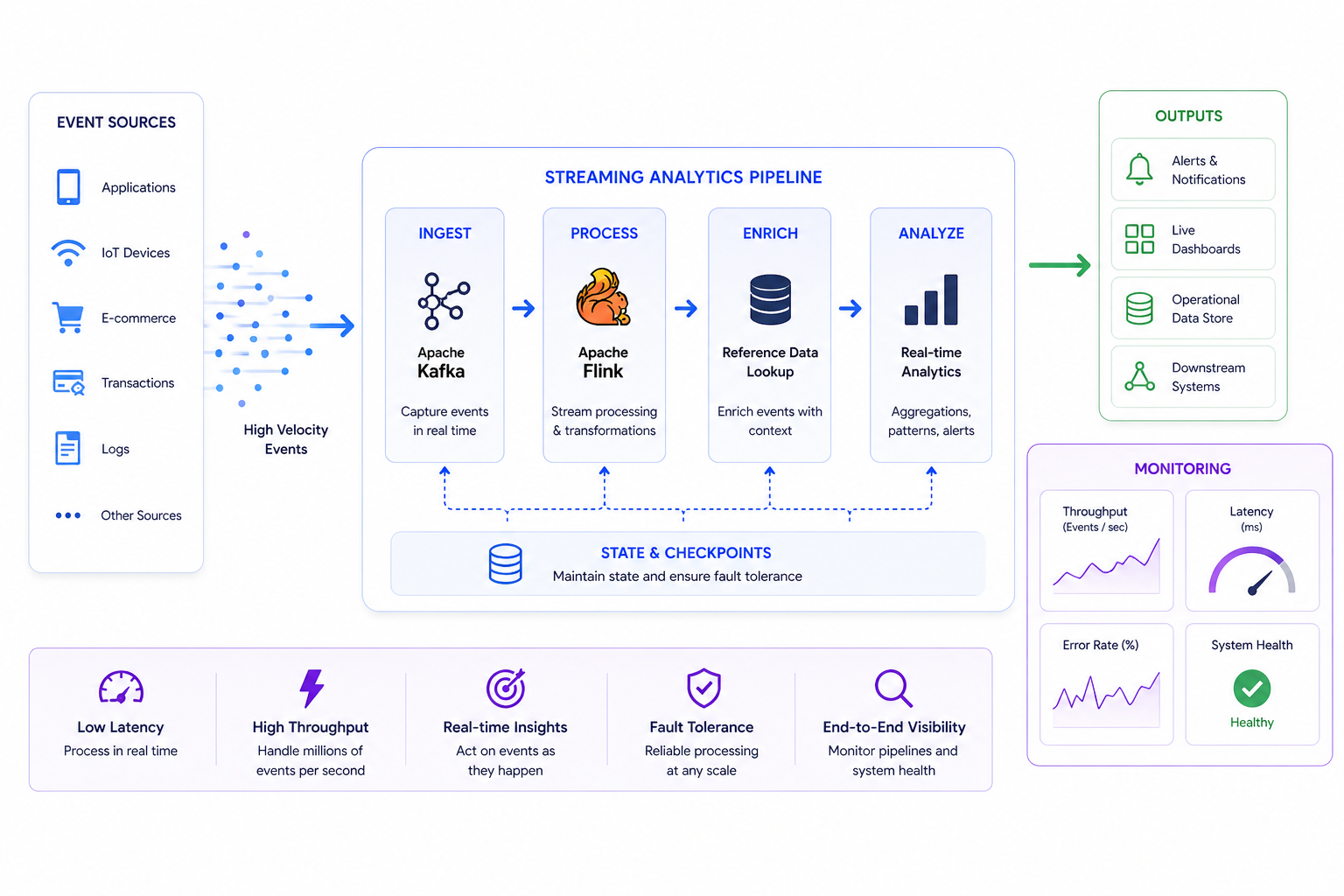
Process high-velocity events with low-latency pipelines and monitoring.
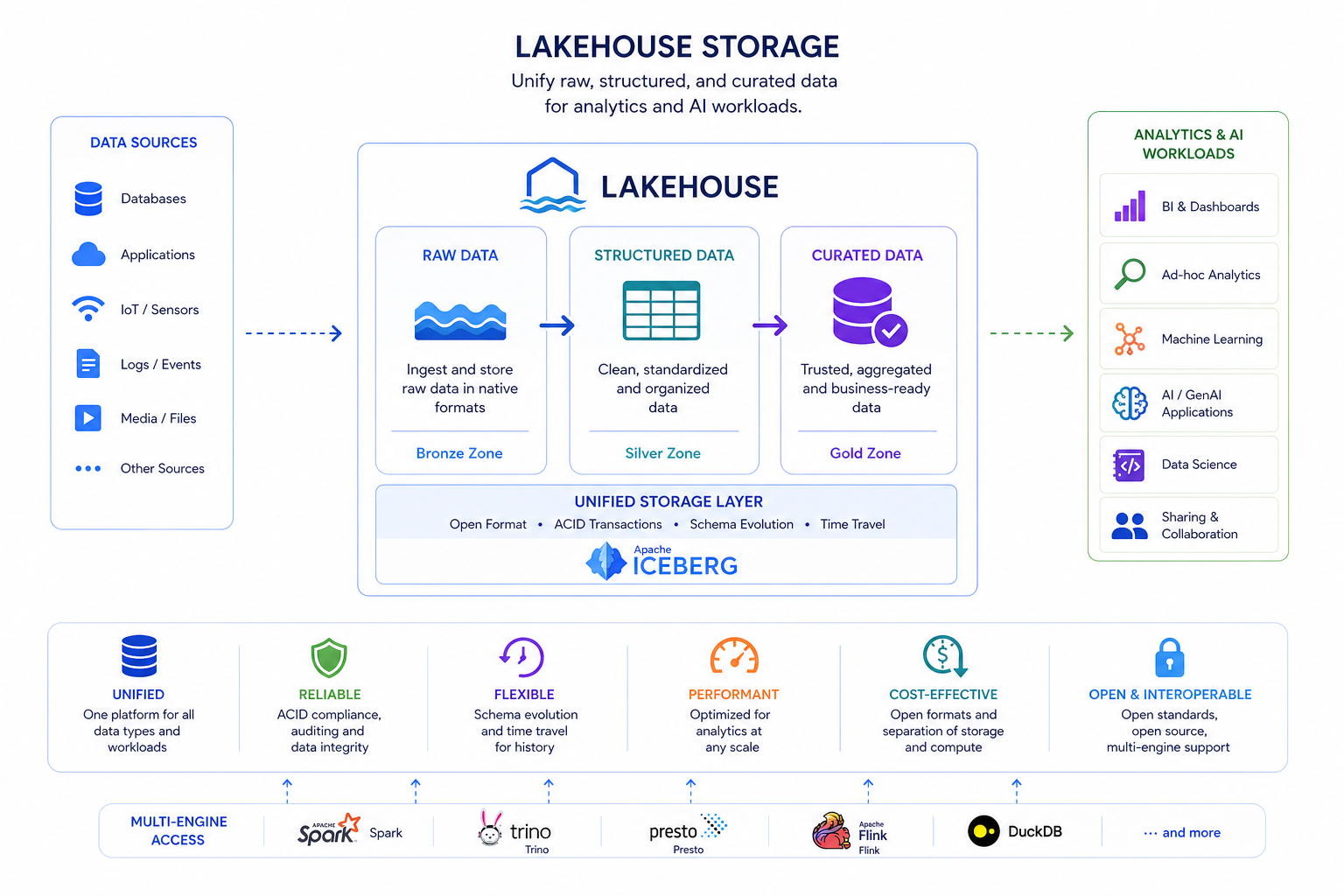
Unify raw, structured, and curated data for analytics and AI workloads.
Architecture
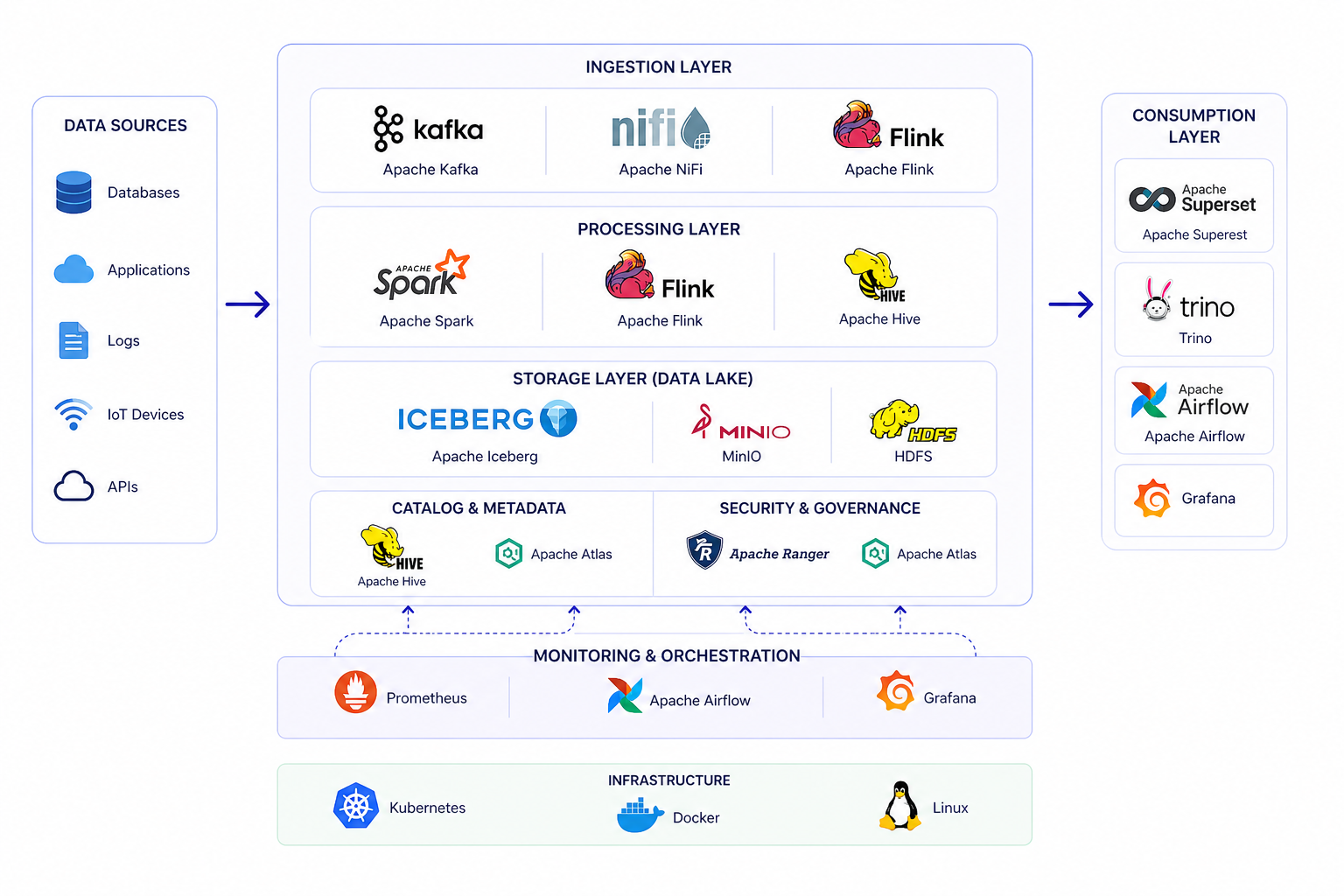
Workflow
Load structured, semi-structured, and unstructured data from many sources.
Organize data in lakehouse layers with scalable object storage and table formats.
Run batch and streaming jobs across distributed compute engines.
Enable high-speed query, dashboards, APIs, and machine learning workloads.
What You Receive
We help you move from isolated storage and slow jobs to a platform that supports analytics, AI, and live operations.
Raw, refined, curated, and serving layers with governance and lifecycle rules.
Distributed batch and streaming jobs designed for volume, latency, and reliability.
SQL access patterns, performance tuning, and data products for business users.
Retention, compaction, cluster sizing, monitoring, and workload management guidance.
Solutions
Build unified storage and compute layers for analytics and AI teams.
Analyze events, logs, transactions, and telemetry as they arrive.
Make large datasets explorable with interactive query engines.
Right-size storage, compute, orchestration, and retention strategies.
Expected Outcomes
Datasets become manageable across storage, processing, and analytics layers.
Queries and pipelines are aligned with how teams actually consume data.
Compute and storage spend becomes visible, tunable, and easier to control.
The same foundation can support BI, AI, data science, and real-time products.
Technology Stack
Ready to scale your data platform?











