Pipelines that do not silently break
We add validation, retry logic, monitoring, and ownership so teams know when data is fresh, delayed, or wrong.
Data Engineering
Move, transform, validate, and deliver trusted data with scalable engineering workflows built for modern analytics and machine learning systems.
Overview
Sachak designs and builds data pipelines that connect business systems, clean and transform raw data, enforce quality rules, and deliver governed datasets to dashboards, data products, and AI workflows.
What We Solve
We add validation, retry logic, monitoring, and ownership so teams know when data is fresh, delayed, or wrong.
Raw source tables become clean, documented, and reusable datasets for dashboards, applications, and AI workflows.
Teams can trace where data came from, who uses it, and how sensitive fields are protected across the platform.
Delivery Blueprint
Identify systems, data owners, refresh needs, schemas, and business-critical datasets.
Choose batch, streaming, orchestration, storage, and quality patterns based on workload needs.
Implement pipelines with tests, monitoring, documentation, and repeatable deployment flows.
Track freshness, failures, cost, usage, and quality so the platform gets stronger over time.
Core Capabilities
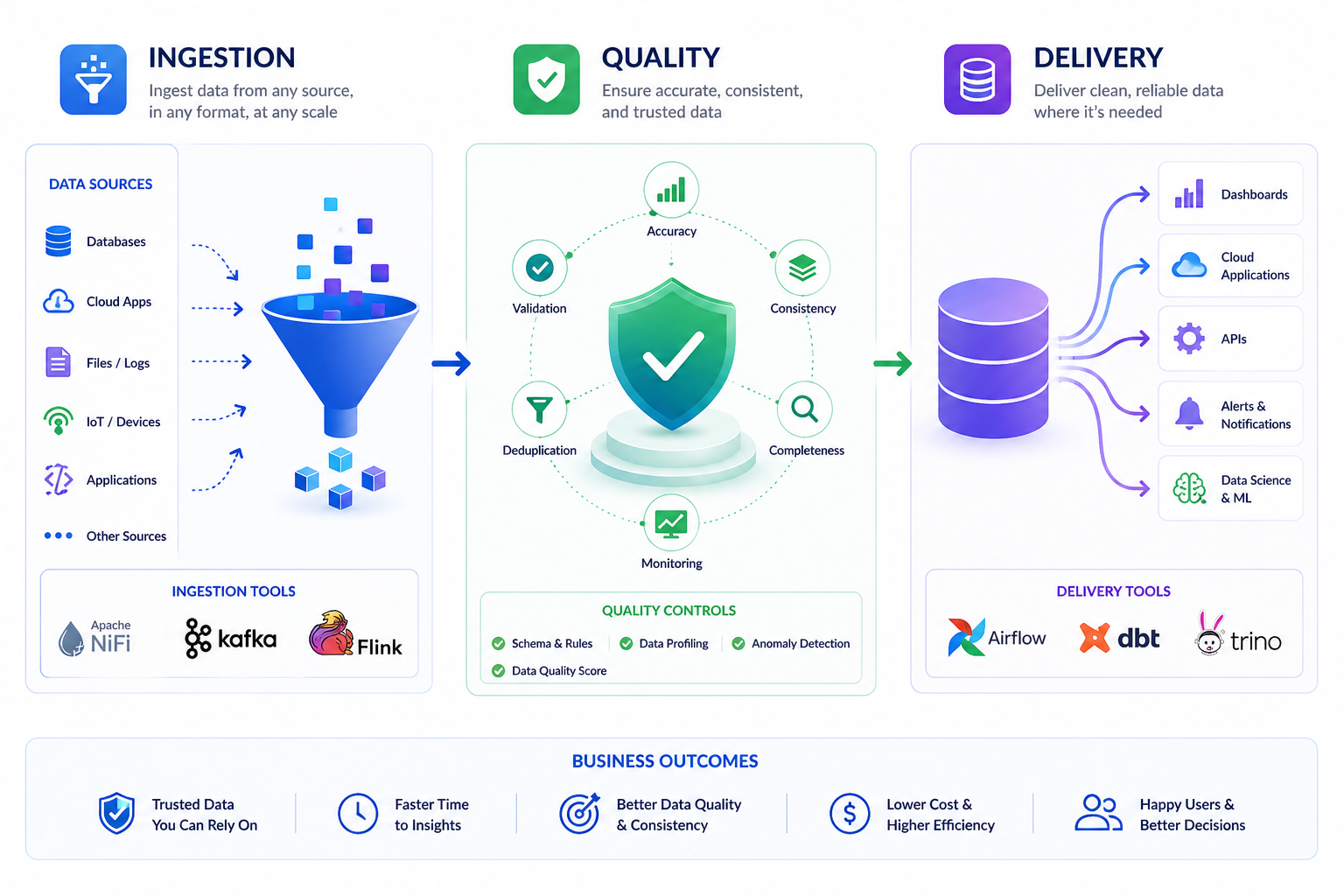
Automate ingestion, transformation, and delivery across business systems.
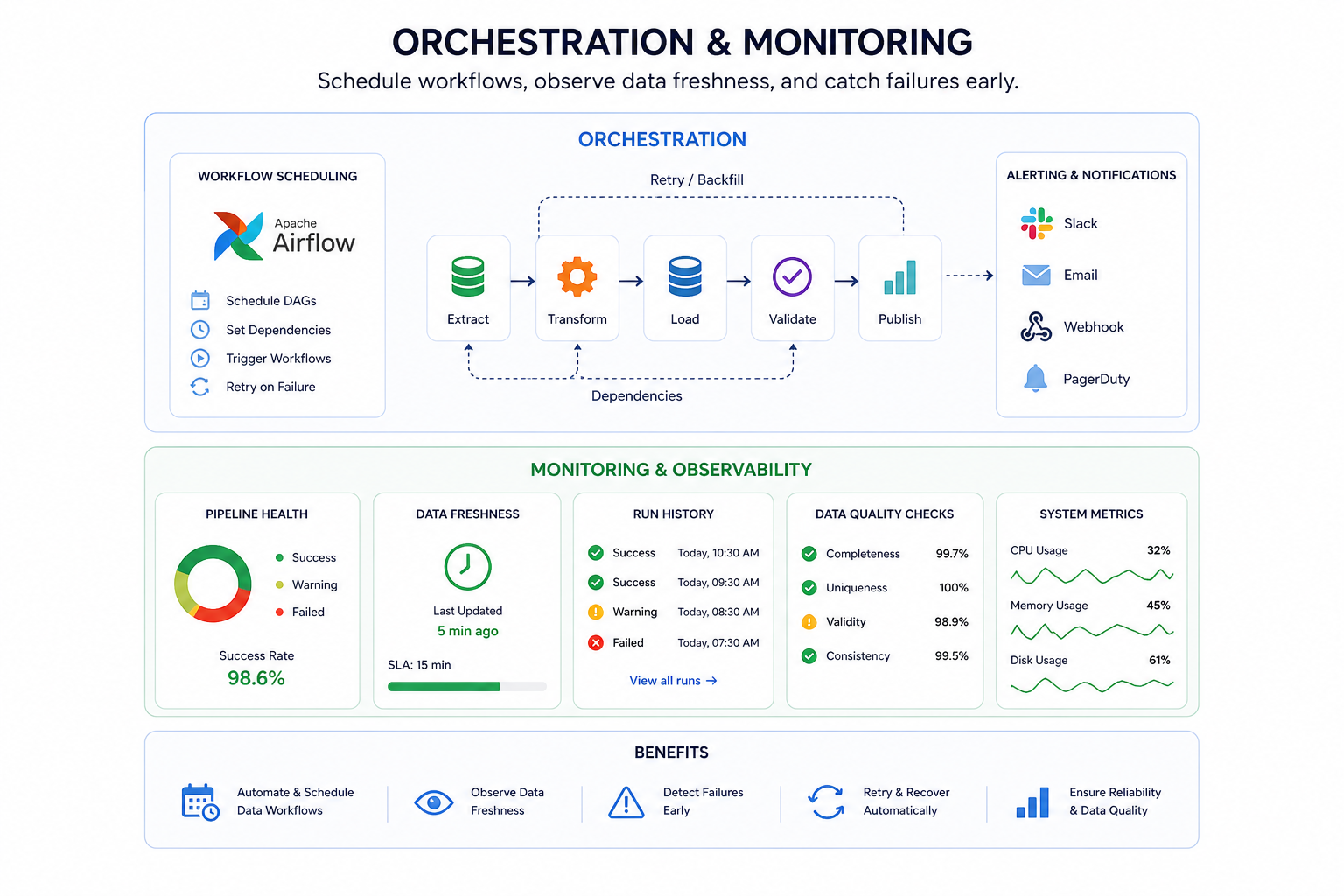
Schedule workflows, observe data freshness, and catch failures early.
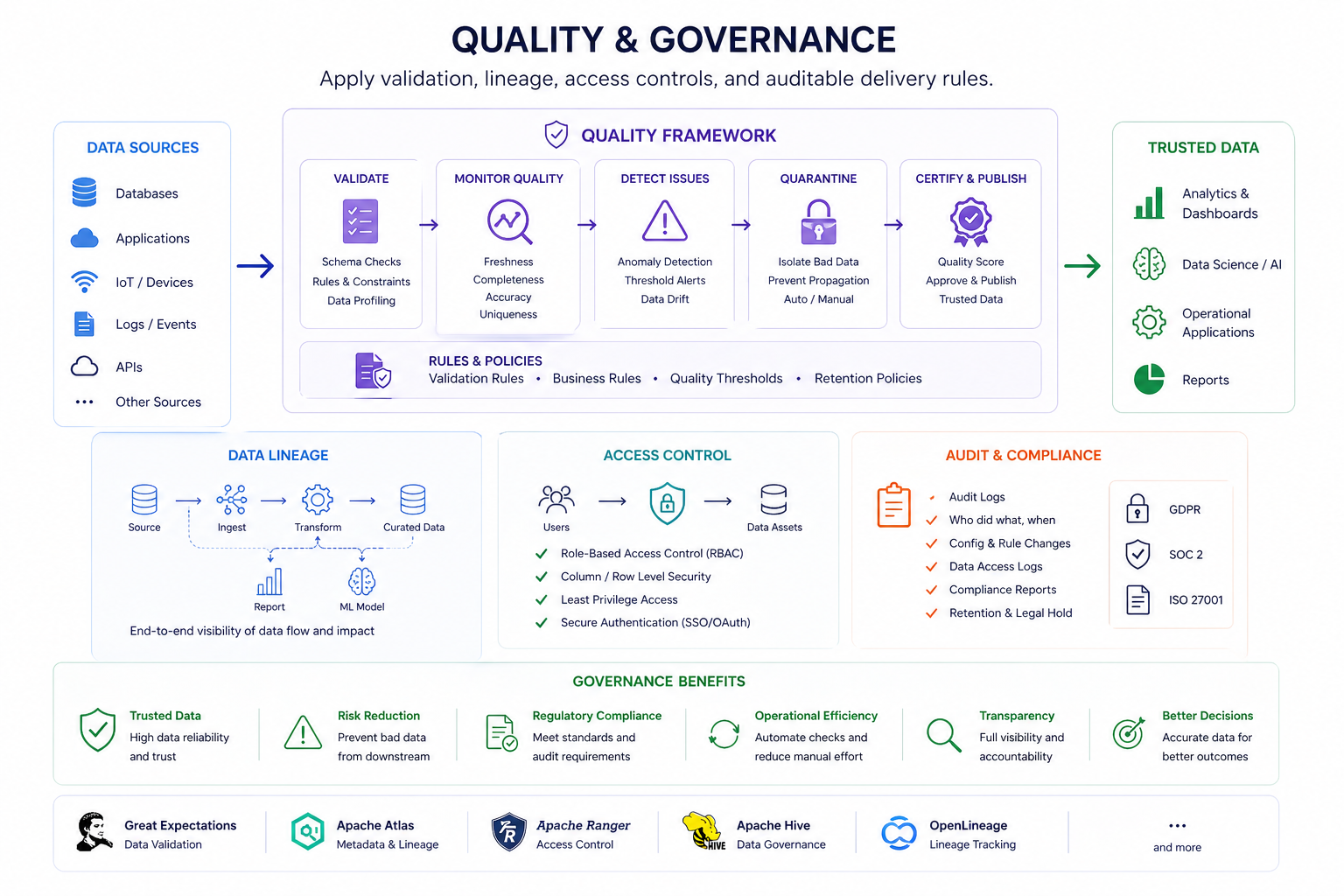
Apply validation, lineage, access controls, and auditable delivery rules.
Architecture
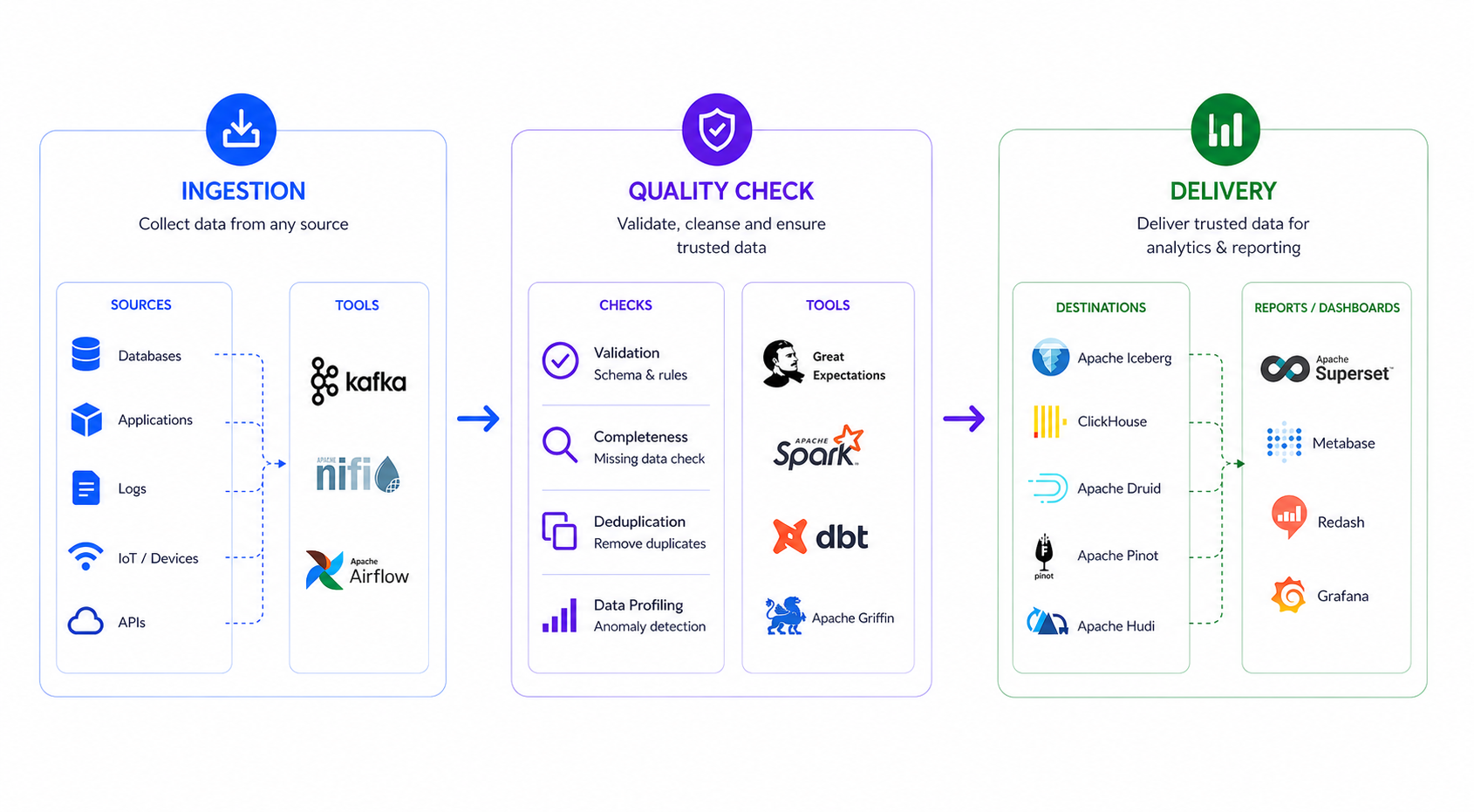
Workflow
Collect data from databases, APIs, files, logs, and streaming event sources.
Clean, enrich, model, and standardize raw data for business-ready use.
Apply quality checks, schema rules, freshness tests, and anomaly detection.
Serve reliable datasets to BI, applications, data science, and operations teams.
What You Receive
Not just code. We deliver operating practices, visibility, and reusable data assets that your team can keep using.
Versioned ingestion, transformation, and orchestration code ready for production operations.
Freshness, schema, completeness, duplication, and business-rule validation where it matters.
Pipeline health, job status, data delays, and operational alerts for support teams.
Clear recovery steps, ownership notes, deployment process, and platform handover materials.
Solutions
Unify operational, customer, finance, product, and third-party data sources.
Schedule, retry, monitor, and operate production-grade data workflows.
Detect missing, delayed, inconsistent, or invalid data before it reaches users.
Prepare curated marts, metrics layers, and governed datasets for reporting.
Expected Outcomes
Broken reports caused by late, missing, or inconsistent data.
Delivery of new datasets for BI, AI, and operational products.
Reusable data assets instead of one-off scripts and manual exports.
Ownership, lineage, access, and operational responsibility.
Technology Stack
Ready to strengthen your data foundation?











